Problèmes d'indexation : Les 12 causes les plus fréquentes qui nuisent à votre SEO
Problèmes d'indexation SEO : 12 causes fréquentes et solutions

⚡ Insight essentiel
Les problèmes d'indexation empêchent des pages web précieuses de rester invisibles dans les moteurs de recherche, entraînant une perte directe de trafic organique et de conversions. Lorsque Google ne peut pas indexer votre contenu, votre site web reste caché à votre public cible, quelle que soit sa qualité. Reconnaître à temps les barrières techniques telles que des configurations robots.txt erronées ou des balises canoniques incorrectes est essentiel pour la visibilité en ligne. En vérifiant systématiquement l'architecture du site, vous pouvez lever ces blocages et renforcer l'autorité de votre domaine.
Pourquoi c'est important
Des problèmes d'indexation persistants minent votre stratégie SEO complète et nécessitent une analyse technique approfondie.
- Les balises noindex dans le code source.
- L'optimisation du sitemap XML.
- Les erreurs serveur et le contenu dupliqué.
Une approche proactive des problèmes d'indexation vous évite de perdre des revenus en raison d'une invisibilité technique.
Qu'est-ce que les problèmes d'indexation et pourquoi nuisent-ils à votre SEO ?
Lorsque nous parlons de la visibilité d'un site web, la base est toujours sa présence dans la base de données des moteurs de recherche comme Google. Les problèmes d'indexation surviennent lorsque les moteurs de recherche ont des difficultés à trouver, crawler ou stocker des pages dans leur index. Ce processus est crucial car une page non indexée n'existe tout simplement pas pour l'utilisateur moyen. C'est comparable à un livre qui a été écrit mais jamais catalogué dans une bibliothèque : personne ne pourra jamais l'emprunter ou le lire. Pour les propriétaires de sites web, cela signifie une perte directe de trafic et de visibilité potentiels.
Sans une indexation correcte, vos textes et produits de valeur restent invisibles pour votre public cible, quelle que soit la qualité du contenu.
L'impact des barrières techniques sur votre classement
Les conséquences de ces lacunes techniques vont au-delà de la simple absence d'une page spécifique. Lorsque Google rencontre à plusieurs reprises des configurations d'indexation erronées, cela peut nuire à la confiance globale dans l'intégrité technique de l'ensemble de votre domaine. Les moteurs de recherche allouent un budget limité au crawl de votre site. Si ce budget est gaspillé sur des impasses ou des ressources bloquées, les pages réellement importantes restent souvent non découvertes. Cela conduit à un cercle vicieux où votre autorité stagne et vos concurrents, qui ont leurs aspects techniques en ordre, vous dépassent sans effort dans les résultats de recherche.
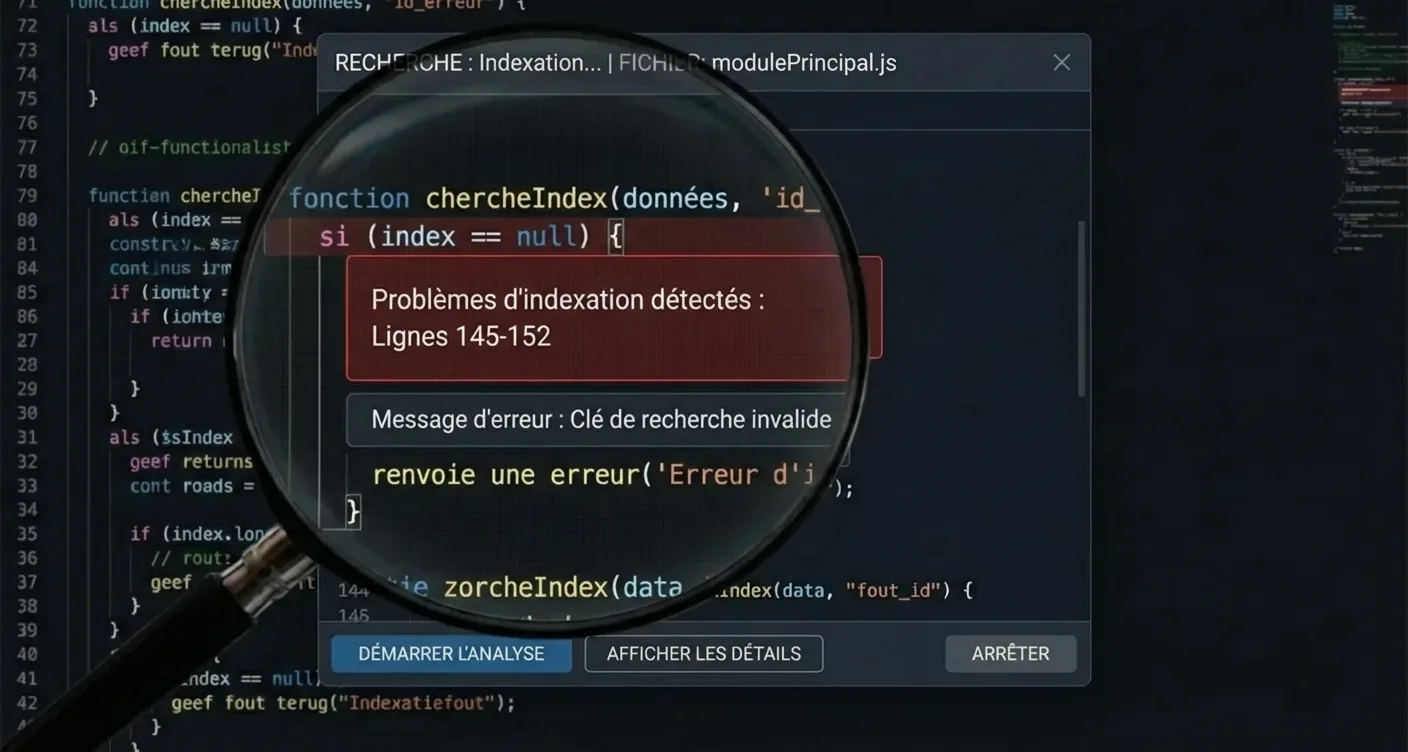
Identifier à temps les problèmes d'indexation pour une meilleure visibilité est essentiel pour toute stratégie de croissance numérique. Souvent, les causes résident dans des fichiers robots.txt mal configurés, des balises noindex oubliées après une phase de test, ou des structures d'URL complexes qui déroutent les crawlers. Dans la pratique, nous constatons que de nombreuses entreprises bloquent inconsciemment leur propre succès en dressant ces murs invisibles pour les moteurs de recherche.
Un site web sain commence par une structure transparente qui invite à l'exploration tant par les visiteurs humains que par les algorithmes.
Pourquoi Google ignore parfois vos pages
ℹ️ Raisons importantes
Diverses raisons peuvent provoquer des problèmes d'indexation, allant du contenu dupliqué aux temps de chargement lents qui découragent le crawler. Google s'efforce de n'offrir à ses utilisateurs que les pages les plus pertinentes et techniquement saines. Si une page contient trop d'erreurs ou ne respecte pas les directives de qualité, le moteur de recherche peut décider de ne pas l'indexer. C'est souvent un signe que des optimisations plus profondes sont nécessaires. Pour ceux qui recherchent un soutien professionnel pour structurer un site web, une visite à SEO Websites peut offrir des informations précieuses pour contourner ces obstacles.
- Configuration incorrecte du sitemap, empêchant la détection de nouveau contenu.
- L'utilisation de balises canoniques pointant vers de mauvaises versions d'URL.
- Erreurs serveur bloquant temporairement ou définitivement l'accès aux moteurs de recherche.
- Pages situées derrière un écran de connexion et donc inaccessibles aux crawlers.
Vérifiez votre fichier robots.txt pour les blocages
Le fichier robots.txt est souvent le premier endroit où les moteurs de recherche se rendent lorsqu'ils visitent votre site web. Ce petit fichier texte agit comme un régulateur de trafic qui détermine quelles répertoires et pages sont accessibles aux crawlers comme Googlebot. Lorsque ce fichier contient des instructions incorrectes, des problèmes d'indexation persistants surviennent immédiatement, ce qui peut gravement nuire à votre visibilité organique. Il est essentiel de comprendre qu'une règle 'Disallow' erronée peut rendre des sections entières de votre site invisibles aux moteurs de recherche, même si le reste de votre SEO technique est parfait.
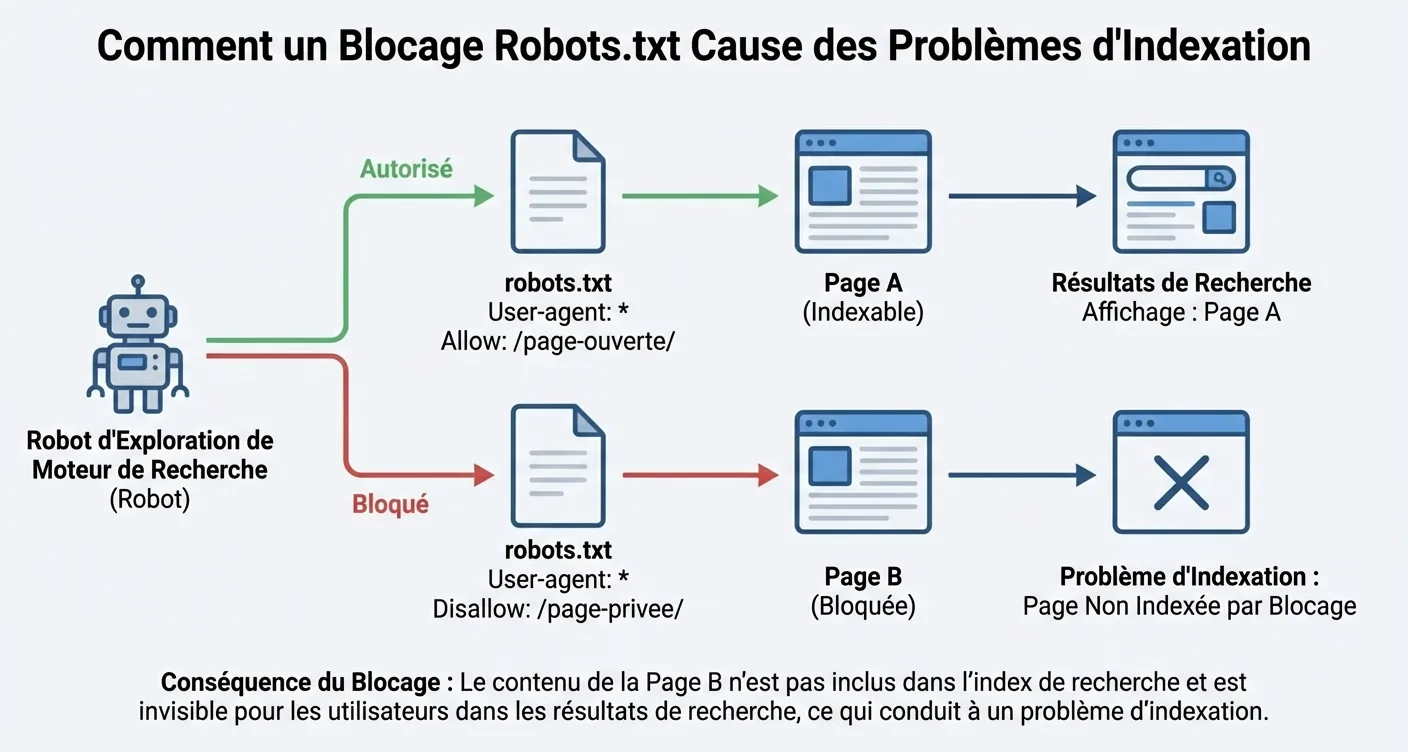
Comment identifier les erreurs critiques dans robots.txt ?
La cause la plus fréquente des problèmes d'indexation liés au robots.txt est le blocage accidentel de l'ensemble du site web après une migration ou pendant une phase de test. Cela se produit souvent en laissant la règle 'Disallow: /', qui indique efficacement à tout bot que l'ensemble du site est un terrain interdit. Il est donc crucial de vérifier régulièrement la syntaxe de votre fichier via des outils comme Google Search Console. Ici, vous pouvez tester spécifiquement si certaines URL que vous souhaitez voir dans les résultats de recherche ne sont pas involontairement bloquées par une règle restrictive dans le répertoire principal de votre serveur.
📋 Optimisez votre flux de travail
En plus de la vérification manuelle de votre code, vous pouvez également utiliser des outils intelligents comme l'Générateur de produits IA pour optimiser votre flux de travail.
Pourquoi c'est important
"Une petite faute de frappe dans votre robots.txt peut faire la différence entre une première position dans Google et une invisibilité totale dans les résultats de recherche."
L'impact de l'efficacité du crawl sur votre classement
Lorsque les moteurs de recherche ont du mal à naviguer sur votre site, ils gaspillent leur "budget de crawl" sur des pages non pertinentes ou se retrouvent bloqués. Cela aggrave les problèmes d'indexation techniques existants, car le nouveau contenu n'est pas détecté et traité à temps dans l'index. En utilisant stratégiquement le fichier robots.txt, vous dirigez les crawlers directement vers les parties les plus pertinentes de votre site web. C'est un instrument puissant pour établir des priorités, à condition de savoir précisément quels répertoires exclure et lesquels ouvrir à l'indexation publique par les moteurs de recherche externes.
⚡ Retenez ceci
N'oubliez pas que résoudre les problèmes d'indexation via la configuration du robots.txt est un processus précis où chaque règle compte pour votre succès.
Pour maintenir la santé de votre site web, vous pouvez prendre les mesures suivantes pour un meilleur contrôle :
📝 Vérifier l'emplacement du sitemap
Vérifiez que l'emplacement du sitemap est correctement mentionné en bas du fichier.
📝 Vérifier les ressources
Vérifiez que les ressources importantes comme CSS et JavaScript ne sont pas bloquées.
📝 Tester avec Search Console
Utilisez le testeur robots.txt dans Search Console pour valider les modifications en direct.
📝 Définition de l'User-agent
Assurez-vous que l'User-agent est correctement défini pour des bots spécifiques.
En testant périodiquement ces éléments, vous évitez que des problèmes d'indexation inattendus n'entravent votre croissance.
Identifier l'utilisation incorrecte de la balise Noindex
⚡ Étape cruciale
Détecter une balise noindex mal placée est une étape cruciale pour résoudre les problèmes d'indexation persistants dans votre stratégie numérique. Lorsqu'une page est accidentellement pourvue de cette instruction, vous indiquez explicitement aux moteurs de recherche d'ignorer complètement le contenu pour les résultats de recherche, ce qui peut être désastreux pour votre visibilité organique. Souvent, cette erreur s'insinue lors de la transition d'un environnement de test vers le site web en direct, les développeurs oubliant de supprimer les blocages destinés à prévenir le contenu dupliqué pendant la phase de construction. L'identification de ces barrières cachées nécessite une approche systématique où le code source et les en-têtes HTTP sont analysés en profondeur pour garantir que les pages de valeur redeviennent visibles pour le public.
Vérifiez toujours d'abord le code source de vos pages de destination les plus importantes pour la présence de la balise meta-robots avec la valeur 'noindex'.
Méthodes techniques de détection

Outre les balises meta standard dans la section HTML, les problèmes d'indexation dus aux paramètres noindex peuvent également être cachés plus profondément dans la configuration du serveur via la balise X-Robots-Tag dans l'en-tête HTTP. C'est une méthode moins visible souvent utilisée pour les fichiers PDF ou les images, mais qui peut être accidentellement appliquée à des répertoires entiers par une configuration erronée dans le fichier .htaccess. Pour vérifier cela efficacement, vous pouvez utiliser des outils spécialisés comme le générateur d'affichage SERP pour voir comment vos pages sont techniquement présentées aux moteurs de recherche. Il est essentiel de comprendre qu'une instruction noindex a toujours la priorité sur une entrée de sitemap, ce qui rend vos pages invisibles malgré vos efforts pour les soumettre.
Leçon importante
"Une seule ligne de code peut faire la différence entre une position de leader et une invisibilité totale dans les moteurs de recherche."
Des audits réguliers de votre site web sont nécessaires pour éviter que de nouveaux problèmes d'indexation n'apparaissent après chaque mise à jour logicielle ou modification de contenu.
Pour obtenir une vue complète de l'état de votre site web, vous pouvez entreprendre les étapes suivantes lors de votre processus d'inspection :
📝 Inspecter le code source
Utilisez la fonction 'Inspecter l'élément' dans votre navigateur pour rechercher 'noindex' dans la section <head>.
📝 Consulter Google Search Console
Consultez les rapports de Google Search Console pour voir quelles pages sont exclues en raison de la balise noindex.
📝 Effectuer un crawl complet
Effectuez un crawl complet avec un logiciel SEO pour localiser à grande échelle les problèmes d'indexation dus à des balises meta erronées.
📝 Vérifier robots.txt
Vérifiez votre fichier robots.txt pour voir s'il existe des instructions conflictuelles bloquant l'accès.
Si vous constatez que des pages importantes n'apparaissent pas dans les résultats de recherche, il est conseillé d'effectuer une analyse approfondie de la structure technique de votre site. La résolution des problèmes d'indexation commence par la compréhension de la hiérarchie des instructions des moteurs de recherche, où la balise noindex constitue souvent le blocage le plus puissant qui doit être levé manuellement.
Problèmes d'indexation dus à une mauvaise structure de liens internes
⚡ Principe fondamental
Une architecture bien pensée de votre site web constitue le fondement de l'optimisation pour les moteurs de recherche. Lorsque la structure de liens internes est chaotique, des problèmes d'indexation surviennent inévitablement. Googlebot et les autres crawlers utilisent les liens pour naviguer d'une page à l'autre. Si des pages importantes sont profondément enfouies dans la hiérarchie ou ne reçoivent aucun lien entrant, elles ne sont tout simplement pas trouvées. Il en résulte un contenu de valeur qui reste invisible pour les visiteurs potentiels, simplement parce que les panneaux techniques manquent pour diriger le moteur de recherche vers la bonne destination au sein de votre domaine.
Sans une structure logique, vous gaspillez un précieux budget de crawl sur des pages non pertinentes tandis que vos pages principales sont ignorées.
L'impact des pages orphelines et des hiérarchies profondes
Les pages orphelines sont des URL qui ne sont liées par aucune autre page du site web. Pour les moteurs de recherche, ces pages sont pratiquement introuvables, ce qui entraîne directement des problèmes d'indexation persistants pour les nouveaux sites web. En outre, la profondeur de clic joue un rôle crucial. Les pages situées à plus de trois ou quatre clics de la page d'accueil reçoivent souvent une priorité plus faible. Une structure plate permet de mieux répartir l'autorité sur l'ensemble du site, donnant à chaque page une juste chance d'être incluse dans les résultats de recherche de Google.
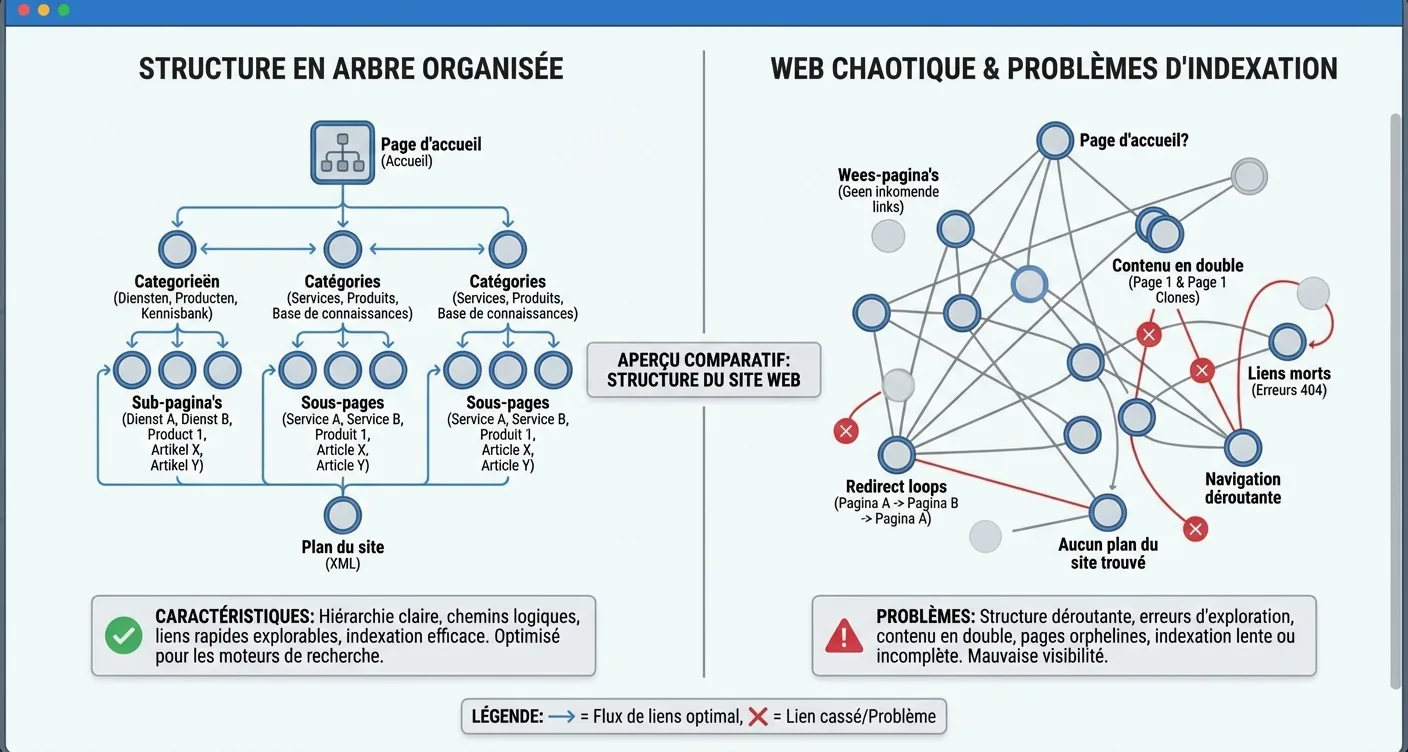
Il est essentiel d'effectuer régulièrement un audit technique pour identifier et résoudre immédiatement ces barrières cachées.
Métaphore
"Un site web sans liens internes est comme une bibliothèque où les livres sont murés. L'information est là, mais personne ne peut y accéder."
Pour résoudre efficacement les problèmes d'indexation, vous pouvez optimiser les éléments suivants au sein de votre structure de navigation :
📝 Structure de menu claire
Utilisez une structure de menu claire qui rend les catégories principales directement accessibles.
📝 Implémenter les "breadcrumbs" (fil d'Ariane)
Implémentez le fil d'Ariane pour aider les utilisateurs et les crawlers à comprendre le contexte d'une page.
📝 Liens textuels pertinents
Assurez-vous d'avoir des liens textuels pertinents au sein de vos articles de blog vers des services ou produits connexes.
📝 Utiliser un sitemap XML
Utilisez un sitemap XML, mais ne vous y fiez pas exclusivement pour une indexation complète.
Améliorer la valeur des liens internes aide non seulement à résoudre les problèmes d'indexation persistants, mais renforce également la pertinence de vos mots-clés les plus importants. En liant stratégiquement avec les bonnes ancres de texte, vous envoyez un signal clair sur le sujet de la page cible. Résoudre les problèmes d'indexation via les liens internes nécessite une approche cohérente où chaque nouvelle page est immédiatement intégrée dans le réseau de contenu existant. N'oubliez pas qu'une forte identité de marque contribue également à l'autorité de votre domaine.
📋 Renforcez votre identité de marque
Vous pouvez pour cela utiliser un générateur de marque afin de renforcer votre image professionnelle.
Une structure de liens saine est le chemin le plus rapide vers un site web entièrement indexé qui performe de manière optimale dans les moteurs de recherche.
L'impact du contenu dupliqué sur votre indexation
⚠️ Attention
Lorsque les moteurs de recherche comme Google sont confrontés à des textes identiques ou très similaires sur différentes URL, une confusion survient dans l'algorithme. Le moteur de recherche doit en effet décider quelle version de la page est la plus pertinente pour l'utilisateur, ce qui entraîne souvent des problèmes d'indexation importants. Au lieu que toutes vos pages obtiennent de bons scores, il peut arriver que la mauvaise page soit affichée ou que l'autorité de votre site web soit fragmentée sur plusieurs URL. Ce phénomène est connu sous le nom de 'cannibalisation de mots-clés', où vos propres pages se concurrencent pour la même position dans les résultats de recherche.
Le contenu dupliqué force les moteurs de recherche à faire des choix que vous préféreriez gérer vous-même pour éviter des problèmes d'indexation persistants.
Comment le contenu dupliqué gaspille votre budget de crawl
Les moteurs de recherche disposent d'un budget de crawl limité pour chaque site web, ce qui signifie qu'ils ne scannent qu'un certain nombre de pages par visite. Si votre site regorge de contenu dupliqué, le crawler gaspille un temps précieux à traiter des informations déjà connues, de sorte que les pages nouvelles ou mises à jour ne sont tout simplement pas détectées. Ce processus aggrave considérablement les problèmes d'indexation sur les grands sites web.
📋 Structure essentielle
Il est donc essentiel d'adopter une structure claire, par exemple en utilisant un architecte de carte produit qui aide à organiser des chemins de contenu uniques.
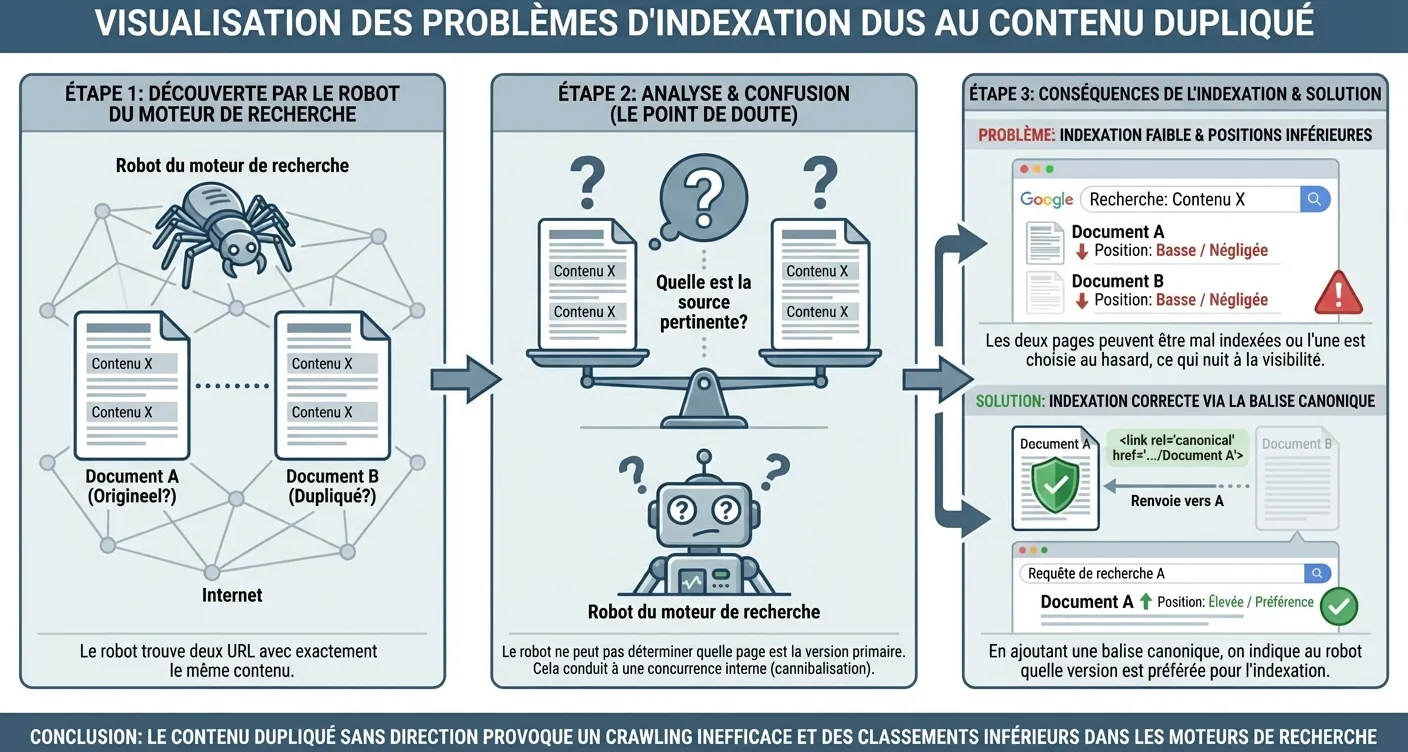
Sans cette orientation, les moteurs de recherche restent bloqués dans une boucle de répétition sans fin, ce qui nuit à la visibilité globale de votre domaine.
Considération importante
"Le contenu dupliqué n'est pas nécessairement une pénalité, mais c'est un frein à l'efficacité qui perturbe gravement la communication entre votre serveur et le moteur de recherche."
Stratégies pour minimiser le contenu dupliqué
Pour limiter l'impact négatif sur votre visibilité, vous devez gérer votre contenu web de manière proactive. L'utilisation de balises canoniques est l'une des méthodes les plus efficaces, car elle indique explicitement au moteur de recherche quelle version d'une page doit être considérée comme l'originale. Ainsi, résoudre les problèmes d'indexation avec des URL canoniques devient une partie intégrante de votre stratégie SEO technique. De plus, il est conseillé d'effectuer régulièrement un audit pour détecter et éliminer les doublons involontaires, tels que les versions imprimables de pages ou les identifiants de session dans les URL.
📝 Utiliser les redirections 301
Utilisez les redirections 301 pour diriger les anciennes pages vers les nouvelles versions uniques.
📝 Définir des paramètres dans Search Console
Définissez des paramètres dans Google Search Console pour exclure les variations d'URL.
📝 Métadonnées uniques
Assurez-vous d'avoir des méta-descriptions et des titres uniques pour chaque page individuelle.
📝 Bloquer les résultats de recherche internes
Empêchez l'indexation des résultats de recherche internes en utilisant robots.txt.
En suivant ces étapes de manière cohérente, vous réduisez les chances de problèmes d'indexation complexes et vous assurez que la valeur unique de votre contenu est pleinement reconnue par les algorithmes.
Erreurs techniques : Budget de crawl et temps de réponse du serveur
⚡ L'épine dorsale de la visibilité
Lorsque nous parlons de la santé technique d'un site web, le temps de réponse du serveur et le budget de crawl constituent l'épine dorsale d'une visibilité organique réussie. Googlebot n'a en effet pas un temps infini pour explorer chaque recoin de votre domaine : il y a une limite stricte au nombre de pages qu'un crawler visite dans un laps de temps donné. Si votre serveur répond lentement ou si trop de scripts inutiles sont chargés, le moteur de recherche perd un temps précieux. Cela conduit inévitablement à des problèmes d'indexation persistants, où le contenu nouveau ou mis à jour n'est tout simplement pas inclus dans les résultats de recherche car le bot a déjà cessé son accès avant d'atteindre les pages pertinentes.
Un serveur lent est souvent la barrière invisible qui empêche vos pages les plus précieuses d'être découvertes à temps par les moteurs de recherche.
Optimisation du budget de crawl
La gestion de votre budget de crawl nécessite une approche stratégique où vous donnez la priorité aux pages qui apportent réellement de la valeur à l'utilisateur. De nombreux sites web sont confrontés à des problèmes d'indexation dus au contenu dupliqué ou à des combinaisons de filtres infinies dans les boutiques en ligne qui piègent le crawler dans un labyrinthe. En utilisant un fichier robots.txt, vous pouvez indiquer aux moteurs de recherche d'ignorer les répertoires non pertinents. Cela laisse plus de place pour les pages principales. Il est essentiel de comprendre que résoudre les problèmes d'indexation techniques via l'optimisation du serveur a un impact direct sur la fréquence et la profondeur du crawl de votre site web par Google.

Outre la structure, le temps de réponse du serveur (TTFB) joue un rôle crucial dans ce processus. Lorsqu'un serveur prend trop de temps pour envoyer le premier octet de données, le moteur de recherche l'interprète comme un signe d'instabilité ou de mauvaises performances. Cela se traduit souvent par une réduction de la fréquence de crawl. Pour éviter ces problèmes d'indexation techniques, il est recommandé d'investir dans un hébergement de haute qualité et des mécanismes de mise en cache. Un serveur rapide permet au bot de traiter plus de pages dans le même temps, ce qui augmente considérablement les chances d'une indexation complète de votre site.
Vérifiez régulièrement vos fichiers journaux pour voir où les crawlers se bloquent ou subissent des retards inutiles lors de leur visite sur votre domaine.
Erreurs serveur et codes d'état
Les codes d'état tels que les erreurs 5xx sont néfastes pour votre réputation auprès des moteurs de recherche. Lorsque Google rencontre à plusieurs reprises des erreurs serveur, le crawler visitera moins souvent le site afin de ne pas surcharger davantage le serveur. Cela crée un cercle vicieux de problèmes d'indexation sur les grands sites web.
📋 Surveillez Search Console
Il est donc très important de surveiller attentivement votre Search Console pour les notifications concernant l'accessibilité du serveur. Pour des informations plus approfondies sur l'amélioration de votre présence en ligne, vous pouvez consulter notre blog.
ℹ️ Points critiques
- Minimisez le nombre de redirections (301/302) pour maintenir la chaîne de crawl courte.
Configuration du sitemap et inspection manuelle d'URL
⚡ Feuille de route pour les moteurs de recherche
Un sitemap XML correctement configuré agit comme une feuille de route pour les moteurs de recherche, leur permettant de naviguer plus efficacement dans la structure de votre site web. Lorsque cette carte contient des erreurs ou fournit des informations obsolètes, des problèmes d'indexation persistants surviennent souvent, entravant la visibilité de vos pages les plus importantes. Il est essentiel que le sitemap ne contienne que des URL canoniques avec un code d'état 200, afin que les crawlers ne perdent pas de temps avec des redirections ou des pages inexistantes. En donnant la priorité au contenu de qualité au sein de votre configuration de sitemap, vous envoyez un signal clair à Google sur les sections de votre domaine qui offrent le plus de valeur à l'utilisateur final.
La soumission manuelle d'URL via Google Search Console est une méthode puissante pour accélérer la résolution des problèmes d'indexation avec les sitemaps.
Inspection et validation manuelles d'URL
L'outil d'inspection d'URL offre un aperçu approfondi de la façon dont Google perçoit une page spécifique et s'il existe des barrières techniques empêchant son inclusion dans l'index. Dans la pratique, de nombreux administrateurs oublient de demander une nouvelle indexation après une modification technique, laissant ainsi des messages d'erreur anciens perdurer inutilement. En utilisant la fonction de test en direct, vous pouvez vérifier immédiatement si le code actuel répond aux exigences du moteur de recherche. Ce processus est crucial pour identifier les problèmes d'indexation dus à des erreurs techniques dans le sitemap, car il permet de combler le fossé entre votre base de données et les résultats de recherche.
Pour affiner votre stratégie, vous pouvez suivre les étapes suivantes pour une configuration optimale :
📝 Supprimer les balises noindex
Supprimez les pages avec une balise 'noindex' du sitemap XML pour éviter toute confusion chez les crawlers.
📝 Regrouper les URL
Regroupez les URL dans différents sitemaps si votre site web contient plus de cinquante mille pages.
📝 Vérifier les rapports de couverture
Vérifiez régulièrement les rapports de couverture pour les notifications spécifiques de problèmes d'indexation.
📝 Emplacement du sitemap dans robots.txt
Assurez-vous que l'emplacement du sitemap est correctement mentionné dans le fichier robots.txt pour une visibilité maximale.
Surveillance constante
La surveillance constante de l'état du sitemap est le seul moyen de garantir la prévention des problèmes d'indexation structurels à long terme.
Si vous constatez que certaines pages ne sont pas incluses malgré un sitemap correct, l'inspection manuelle offre une solution. Vous pouvez voir si la page a été crawlée mais pas encore indexée, ce qui indique souvent un manque d'autorité ou de contenu unique. En combinant ces informations avec une structure de sitemap rigoureuse, vous minimisez considérablement les risques de problèmes d'indexation pour les nouveaux sites web.
Plan d'action pour résoudre définitivement vos problèmes d'indexation
✨ Résoudre définitivement les problèmes d'indexation
Traiter structurellement les problèmes d'indexation nécessite une analyse approfondie des fondations techniques de votre site web. Lorsque Google ignore certaines pages, la cause réside souvent dans une structure de liens internes déficiente ou des configurations erronées dans le fichier robots.txt. Il est essentiel de vérifier d'abord si les URL concernées n'ont pas été accidentellement exclues via une balise noindex. En supprimant systématiquement chaque barrière, vous vous assurez que les moteurs de recherche peuvent naviguer facilement dans votre contenu et l'inclure correctement dans leur base de données pour les requêtes de recherche pertinentes des utilisateurs.
La résolution efficace des problèmes d'indexation commence toujours par un audit complet des données de Google Search Console pour identifier les schémas d'erreurs.
Optimisation technique et sitemaps
Une étape cruciale dans ce processus est la soumission d'un sitemap XML mis à jour. Ce fichier agit comme une feuille de route pour les crawlers et aide à prioriser les pages importantes. Vérifiez également que votre serveur répond rapidement : des temps de chargement lents peuvent en effet entraîner un abandon prématuré des crawlers, ce qui conduit indirectement à des problèmes d'indexation persistants pour les nouveaux sites web. Assurez-vous que toutes les balises canoniques sont correctement configurées pour éviter le contenu dupliqué, car la confusion sur la source originale entraîne souvent l'exclusion de pages des résultats de recherche.
Suivez ces étapes pour un résultat optimal :
📝 Vérifier le statut des URL
Vérifiez le statut de vos URL dans la Google Search Console.
📝 Contrôler le sitemap
Vérifiez l'accessibilité de vos pages les plus importantes via le sitemap.
📝 Supprimer les redirections inutiles
Supprimez les redirections inutiles qui grèvent inutilement le budget de crawl.
📝 Optimiser la valeur des liens internes
Optimisez la valeur des liens internes vers les pages plus profondes.
Règle d'or importante
"Un site web sain est un site web où chaque page de valeur est accessible en moins de trois clics, tant pour l'utilisateur que pour le bot des moteurs de recherche."
Il est en outre judicieux d'effectuer régulièrement des inspections manuelles pour les URL spécifiques qui prennent du retard. Utilisez l'"outil d'inspection d'URL" pour demander une indexation immédiate après avoir effectué des modifications. Résoudre les problèmes d'indexation via le SEO technique est un processus continu qui doit être surveillé de près pour garantir un succès à long terme. N'oubliez pas que la qualité du contenu reste la base : même avec la meilleure technique, Google refusera d'indexer des pages qui n'offrent pas de valeur ajoutée. En faisant de l'analyse des problèmes d'indexation complexes une partie intégrante de votre maintenance, vous maintenez une forte visibilité en ligne.
ℹ️ Conseil important
Restez toujours vigilant face aux baisses soudaines du nombre de pages indexées dans votre tableau de bord.
⚡ Idée clé
Identifier à temps les problèmes d'indexation est essentiel pour votre visibilité en ligne.
📋 Fondement du SEO
En s'attaquant systématiquement aux obstacles techniques tels que les configurations robots.txt erronées ou une structure de liens internes déficiente, vous posez une base solide pour votre stratégie SEO. Vérifiez donc régulièrement vos données Search Console pour identifier et résoudre rapidement les blocages.
Prêt à résoudre vos problèmes d'indexation ?
En bref, la résolution des problèmes d'indexation persistants exige une attention particulière tant à la configuration technique qu'à la qualité globale de votre contenu. Qu'il s'agisse de supprimer les balises noindex, d'optimiser votre sitemap ou d'améliorer la vitesse de chargement, chaque ajustement contribue à une meilleure visibilité dans Google.
Commencez un audit dès aujourd'hui →Assurez-vous que vos pages de valeur obtiennent les positions organiques qu'elles méritent.
❓ Qu'est-ce que les problèmes d'indexation exactement ?
Les problèmes d'indexation surviennent lorsque les moteurs de recherche comme Google ne parviennent pas à inclure les pages de votre site web dans leur base de données. En conséquence, votre contenu est introuvable pour les utilisateurs, ce qui a un impact négatif direct sur votre trafic organique.
❓ Comment puis-je vérifier si mon site web souffre de problèmes d'indexation ?
Vous pouvez le vérifier facilement via Google Search Console sous le rapport 'Pages'. Si vous remarquez que des URL importantes sont marquées comme 'Exclues', il est fort probable que vous ayez affaire à des problèmes d'indexation spécifiques qui doivent être résolus.
❓ Pourquoi un fichier robots.txt bloque-t-il parfois l'indexation ?
Un fichier robots.txt contient des instructions pour les moteurs de recherche sur les parties du site qu'ils ne doivent pas visiter. Si une règle 'Disallow' a été accidentellement définie pour des répertoires importants, cela bloque l'accès et empêche les pages d'être indexées.
❓ Quand les nouvelles pages deviennent-elles généralement visibles dans les résultats de recherche ?
Ce processus peut varier de quelques heures à plusieurs semaines, en fonction de l'autorité de votre site web. En soumettant un sitemap XML et en demandant une indexation manuelle, vous pouvez accélérer ce processus et éviter les retards.
Articles similaires
- Audit de page web
Découvrez comment un audit de page web peut identifier rapidement les causes d'un mauvais classement et les correctifs les plus efficaces. Checklist.
- Audit SEO : Classez-vous plus haut sur Google, commencez ici
Envie de plus de trafic organique ? Faites un audit SEO professionnel, découvrez les points d'amélioration et commencez à grandir sur Google dès aujourd'hui !
- Audit Technique Multilingue: Optimisez Votre Stratégie SEO
Améliorez votre visibilité internationale. Notre audit technique multilingue identifie les points critiques pour optimiser votre site et booster votre SEO.
- Prioriser le plan d'action audit: Un guide étape par étape
Découvrez comment prioriser efficacement votre plan d'action d'audit SEO pour un impact maximal. Optimisez vos processus et boostez vos résultats !
- Core Web Vitals et Contenu
Améliorez votre référencement avec les Core Web Vitals. Découvrez l'impact du LCP, INP et CLS sur la performance et l'expérience utilisateur de votre site.